5
Model families
Several months. Five model families. Eighteen real-world problems. Fifty attempts each. One stubborn conclusion: most enterprise AI failures aren't model failures — they're orchestration failures.





Most people approach AI from one of two extremes — AI is a magic wand, or AI can't do serious work. The reality is much more nuanced.
Over the last several months I tested agents against eighteen real-world programming problems inside a simulated multi-tenant medical-practice management application. Each agent attempted every task fifty times inside a resettable sandbox. Between runs, the environment was reset so the model started from identical conditions.
Every agent had the same baseline toolkit:
Enough for a reasonably capable agent to navigate a real codebase — but in the with-context condition, I added something more important.
The agents gained access to a knowledge graph containing architectural documentation, historical issues, conventions, blast-radius analysis, MCP retrieval, and LSP semantic navigation. In practice, the kind of contextual memory a senior engineer develops over years.
What surprised me wasn't that performance improved. It was how dramatically.
Task completion in selected scenarios. The reasoning model itself did not change. The environment around the model did.
A large portion of software engineering is not raw intelligence. It is orientation.
Senior engineers are often effective not because they are "smarter" in the abstract, but because they know:
Modern AI systems exhibit the same patterns. With the right contextual scaffolding, even smaller models improved substantially. The orchestration layer increasingly determines the quality ceiling.
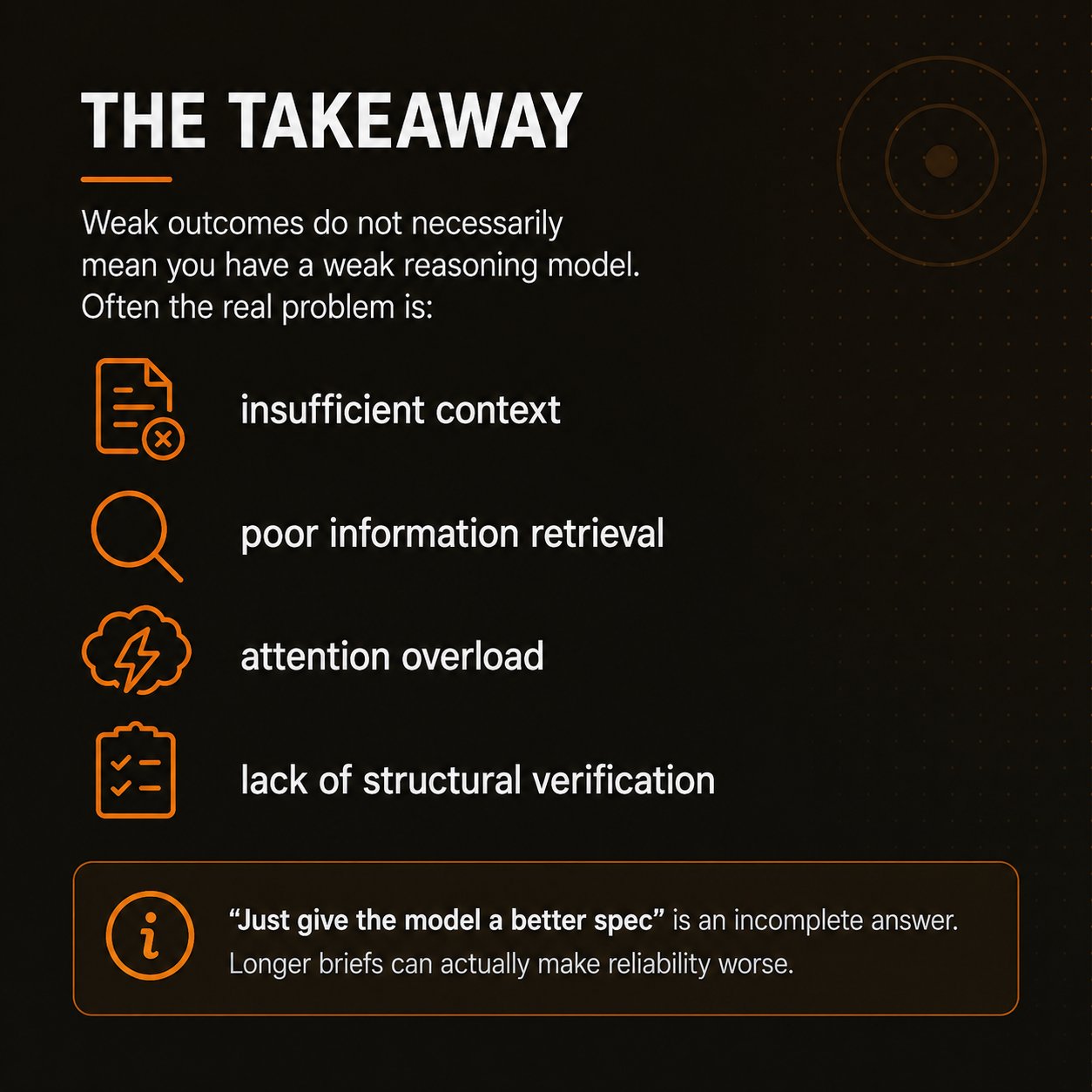
Most enterprise AI failures are orchestration failures, not raw model failures.
Agents forget things. Not metaphorically. Operationally.
Given long briefs or large specifications, agents would sometimes:
In adversarial-doc tests, less-disciplined agents confidently modified working systems to match wrong documentation. The failure modes aligned closely with human cognitive overload.
The more information I dumped into a prompt, the worse reliability often became. That contradicts a common intuition: "if the model failed, just provide a better spec." In practice, longer briefs frequently increased failure rates.
Several orchestration patterns consistently improved outcomes.
Bring in only what's needed, when it's needed.
Agents retrieve — they don't have to recall.
Structure reduces variance.
Know what touching X will affect.
Define done. Make it verifiable.
Let agents verify and improve their own work.
Look first. Act second.
Surface relevant context proactively.
These map directly onto deployment surfaces available today in Claude Code, Cursor, and the OpenAI Agent SDK. Any enterprise engineering organization could implement many of them immediately.
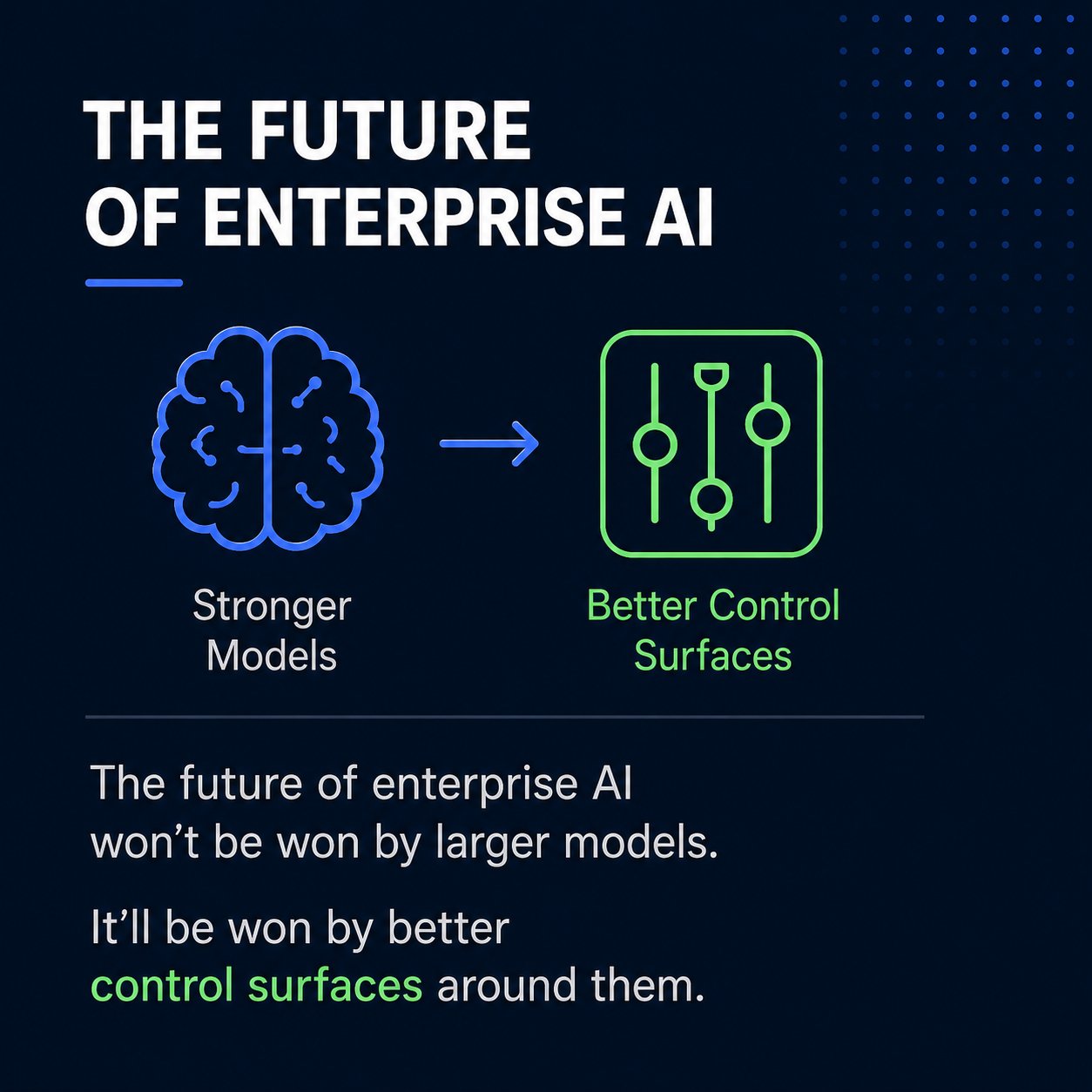
The future of enterprise AI will not be won purely through larger models.
Larger models help. But bigger models alone do not solve:
Those are systems engineering problems. The organizations that win in enterprise AI will be the ones that build the best control surfaces around models.
That fragility does not necessarily indicate a weak reasoning model. Often it indicates weak orchestration.
I'll likely publish additional findings around retrieval systems, tool orchestration, agent reliability, attention management, workflow constraints, and enterprise deployment patterns. A more formal paper may follow — because increasingly, that feels like the real frontier.
Roderick Bertoncini
Founder, Mente360
Building practice-management software, and occasionally writing about how it gets built.
See how Mente360 can help you spend less time on admin and more time with clients.